以太网收发包接口说明手册
目录
1 适用人员
适用于基于siflower以太网驱动源码,需要了解siflower以太网方案收发包接口的人员。
2 开发与测试环境
SF19A2890芯片开发平台及源码环境
3 硬件介绍
下图为gmac硬件架构介绍
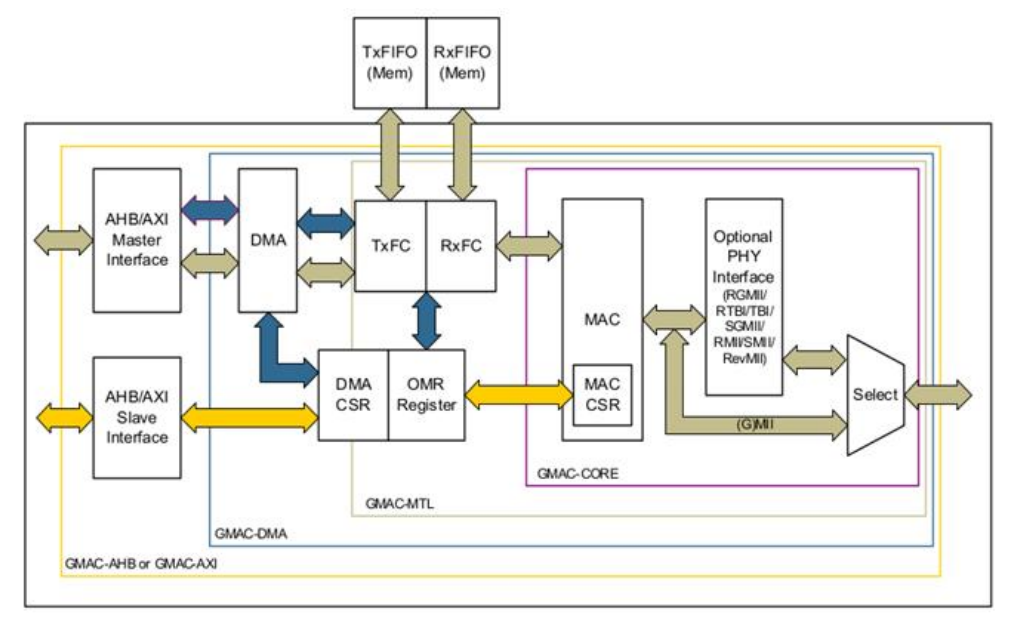
- GMAC-AHB
GMAC-AHB 模块通过AHB master接口向系统的内存传输数据。系统的cpu通过64位宽的AHB slave接口来访问GMAC 内部的控制寄存器和状态寄存器
- GMAC-DMA
DMA模块有独立的收发功能,还有独立的寄存器,发送功能将数据从系统内存搬运到设备端口(MTL),接收模块将数据从设备端口搬运到系统内存中,控制器通过描述符来高效的进行数据收发,尽可能的减小CPU的介入。 DMA被设计为一个面向数据包的数据收发模块,也就是以太网传输中的一帧,控制器可以以设置为每次一帧收发完成后向cpu发送中断,或者其他正常或异常情况下触发中断。
GMAC-MT MTL模块由两组FIFO组成,发送FIFO可以软件控制阈值,接口FIFO也可以使用软件控制阈值(默认64字节)。
GMAC-CORE MAC根据PHY芯片不同支持多种接口,PHY接口智能在reset之后设置一次,MAC应用层通信基于MAC发送接口(MTI),MAC接受接口(MRI)和MAC控制接口(MCI)。
3.1 MAC功能
GMAC的功能被划分成下面几个类别
1)协议标准功能
2)MAC
3)DMA模块
4)收发层(MTL)
协议标准功能
IEEE 802.3-2008 for Ethernet MAC
IEEE 1588-2008 standard for precision networked clock synchronization
AMBA 2.0 for AHB master and slave ports
RGMII/RTBI specification version 2.6 from HP/Marvell
RMII specification version 1.2 from RMII consortium
MAC
MAC层支持下列功能
- 10、100、100Mbps 传输速度,通过下列phy接口
- RGMII 接口, 和外部千兆 PHY进行通讯
- RMII接口,和外部高速以太网PHY进行通信
- 全双工模式
- 支持IEEE802.3x flow control 在对输入进行流控的是否,自动发送zero-quanta Pause frame
- 可以选择是否将接收的Pause frames转发给用户程序。
- 半双工模式
- 支持CSMA/CD Protocol Flow control using backpressure support (基于 implementation-specific white papers and UNH Ethernet Clause 4 MAC Test Suite - Annex D)
- 半双工千兆模式下帧突发和帧拓展
发送中前导和帧数据起点(SFD)插入
接受中前导和帧数据起点(SFD)删除
基于每一帧进行自动CRC校验和数据填充控制
接收帧进行填充数据和CRC数据剥离
- 灵活的地址过滤模式:
- 31个额外的48 bit 目的地址(DA)过滤器,每字节都可以设置掩码。
- 31个48 bit 来源地址(SA)对比检查,每字节都可以设置掩码。
- 针对广播或者单播(DA)地址的256 bit的hash过滤器
- 可以选择通过所有多播帧
- 用于网络监听的混杂模式接收所有帧,不进行任何filter
- 传入所有报文并含有状态报告
支持可编程帧长度,支持标准或者jumbo 以太网帧,最大长度16KB
可以编程帧间隙(IFG)(40-96 bit 时间间隔 最单元8 )
可选择使用发送帧的时候减小前导帧长度
对于发送和接收报文有独立的32bit 状态
识别接受报文的IEEE 802.1Q vlan tag
- 额外报文过滤:
- 根据VLAN TAG : 完全匹配和基于HASH过滤
- 基于层三和层四进行过滤, IPV4 IPV6上的TCP和UDP 4个L3 1个L4
网络状态统计(可选)RMON/MIB计数(RFC2189/RFC2665)
可以选择侦测远程唤醒帧和AMD幻数包
可以选择硬件checksum
对于接收的封装在以太网帧中的IPV4和TCP进行校验(TYPE 1)
可以选择强化接收模块。对于ipv4 头部的checksum 以及封装在IPv4?IPv6中的TCP和UDP iCMP 报文进行checksum校验
可以选择支持以太网帧的时间戳功能,遵照协议IEEE 1588-2002 和 IEEE 1588-2008,对于发送或者接收帧,会被赋予一个64bit的时间戳。
MDIO master接口来对接PHY设备,进行配置和管理
发送对于每一帧可以进行CRC 替换 ,原地址插入或者替换,VLAN的插入替换删除等功能
可以选择4个通用主题的输入或者输出
- 通用主题的输入可以编程为在上升沿还是下降沿触发中断
- 10、100、100Mbps 传输速度,通过下列phy接口
DMA BlocK
DMA模块在系统内存和MTL之间传输数据,host可以使用DMA寄存器(DMA CSR)来控制DMA操作。 DMA模块包含以下功能:
64bit数据传输
单channel的发送和接收模块
全同步设计,工作在一个系统时钟下(除了给CSR单独配一个CSR时钟源)
对于面向报文的DMA传输同时带有帧分隔符进行了优化
支持按照字节对其的数据buffe地址
支持双buffer (ring)或者 链表(chained) 的描述符链。
描述符的结构设可以一次传输大量数据,而不需要cpu太多参与(每个描述符最多可以传输8K数据)
针对正常操作或者收发错误有全面的状态报告
可以独立配置的burst大小,可以让DMA模块达到最优化使用host总线。
可以编程的各种情况下的对于中断的选择
针对每帧的收发可以完全进行中断控制
在收发模块间使用Round-robin 或者 fixed-priority arbitration算法调度
对于寄存器访问和数据接口分开为单独接口
收发层(MTL)
MTK模块由两组fifo组成,带有可编辑阈值的发送fifo,和带有可编辑阈值的接收fifo(默认64 byte)。
MTL层支持下面功能:
64位的收发模块(将应用层和GMAC-CORE连接在一起)
128字节,256字节,512字节,1KB,2KB,4KB,8KB,16KB或者32KB接收端FIFO大小
在GMAC-MTL配置中可选择接口在MTL Rx FIFO的顶端标示接受侦的长度。
在GMAC-MTL配置中可编程burst长度,用于启动burst,最大为MTL Rx和Tx FIFO的一半
EOF传输后将接收状态向量插入接收FIFO,这使得接收FIFO中的多帧存储无需另一个FIFO来存储这些帧的接收状态。
Cut-Through或Threshold模式下的可配置接收FIFO阈值(默认固定为64字节)
可以选择在接收时过滤所有错误帧,而不是在存储转发模式下将它们转发到应用程序
可选择转发尺寸不足的正确帧
通过为接收FIFO中丢弃或损坏(由于溢出)的帧生成脉冲来支持状态统计
传输FIFO大小可以为256字节或512字节或1KB,2KB,4KB,8KB或16KB
存储和转发机制用于传输到MAC
发送缓冲区管理的可以设置阈值
随时可以配置在FIFO中存储的帧数,默认值是两个帧(固定)包含内部有DMA,GMAC-MTL配置最多有八个帧
根据接收FIFO填充情况(设定阈值)来自动生成暂停帧或反压信号到MAC
发送中自动重发碰撞帧
丢弃晚期碰撞,过度碰撞,过度延期和欠载情况下的帧
软件控制清除TX FIFO
非活动状态下禁用数据FIFO RAM芯片选择非活动状态以降低功耗
可选模块用于计算并插入以存储转发模式传输的帧中的IPv4报头校验和和TCP,UDP或ICMP校验和
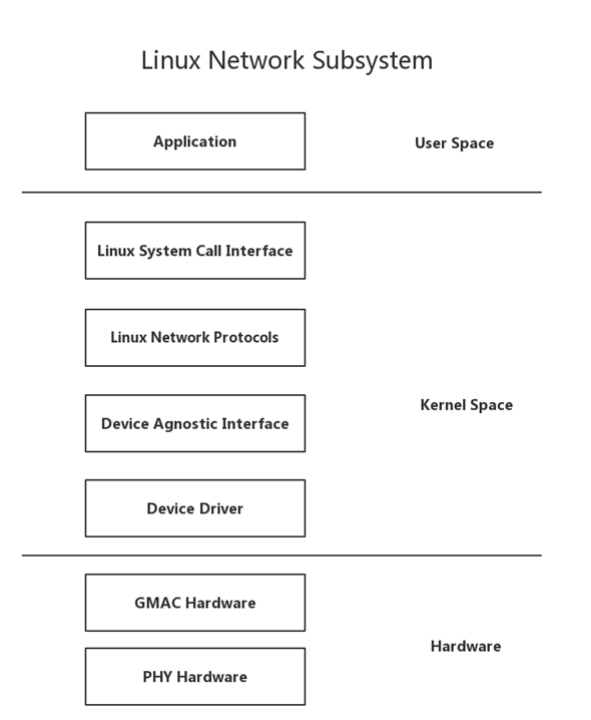
3.2 Linux网络堆栈的高级视图
Linux将内核空间的网络级别划分为4个子层。
Linux网络子系统的顶部是Linux系统调用接口层。
它为用户提供了访问内核网络子系统的套接字。
下面是Linux网络协议层,其中包括TCP,UDP,IP和其他协议。
还有一个设备不可知界面层,它提供了协议和设备驱动程序之间的通用接口。
最后是控制MAC和PHY硬件的设备驱动层。
Device Agnostic Layer将协议连接到不同的网络驱动程序,并为底层网络设备驱动程序提供一些可以操作高级协议栈的常用功能。
如果网络协议层需要将数据包传输到设备驱动程序,则需要调用dev_queue_xmit()函数,该函数对数据包队列进行排序,并从设备驱动程序层调用ndo_start_xmit()函数来完成传输。
接收通常由napi_schedule()函数运行。当底层设备收到中断时,它会调用napi_schedule9()函数将数据传输到设备不可知界面层。
3.2.1 网络协议层和设备与媒体层之间的细节
网络接口层为网络协议提供统一的分组收发器接口。 无论协议是ARP还是IP,它总是通过dev_queue_xmit()函数发送数据,并通过napi_schedule()函数接收数据。 该层使网络协议独立于特定设备。
网络设备接口层提供了一个统一的结构net_device,用于向协议接口层描述特定的网络设备特性和操作,协议接口层是设备驱动程序功能层中每个功能的容器。
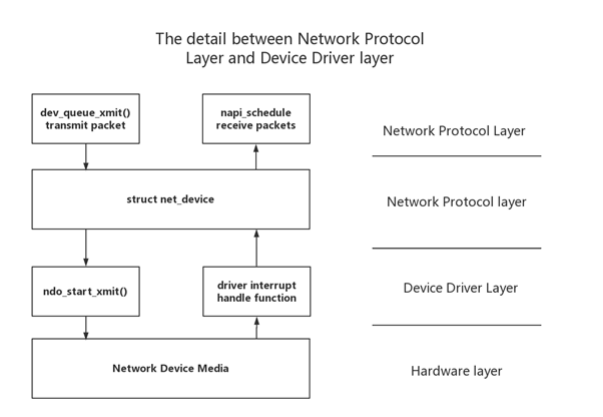
设备驱动程序层包含结构net_device的具体成员,并且很难完成适当的操作。 它通过ndo_start_xmi()函数发送数据,并通过中断句柄函数接收数据。
网络设备和媒体层是完成数据包收发的物理实体,包括网络适配器和特定的传输介质。 它们由设备驱动程序层中的功能驱动。
4 Siflower GMAC 驱动
4.1 驱动架构
GMAC设备驱动程序包含3个文件:sgmac.c,sgmac.h,Makefile。
在sgmac.c中,有描述符操作,平台功能,设备功能和网络层相关接口,而在Makefile中,有编译的方式(与NPU在同一个Makefile中)。
我们把所有这些东西放在一个文件中,因为没有太多的东西,但它仍然是一个不好的行为。 也许我们会进一步重建架构。
4.2 设备驱动程序层包含结构net_device的具体成员
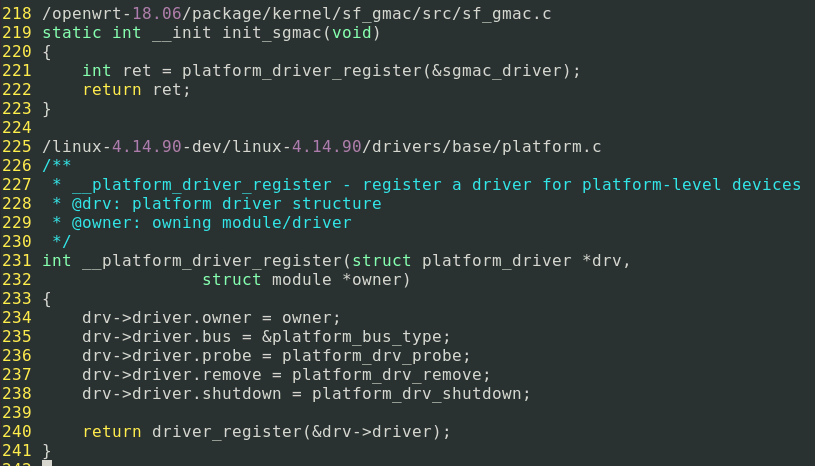
设备驱动程序是使用前面部分提到的驱动程序代码的平台和操作系统设备不可知层开发的。
Linux首先将GMAC设备视为平台设备。 这由platform_driver结构表示。该设备接口的重要成员在下面给出。
struct platform_driver {
int (*probe)(struct platform_device *);
int (*remove)(struct platform_device *);
...
};
Linux中的网络堆栈将GMAC设备视为网络接口/设备。 这由net_device结构表示。 下面给出了此设备接口的重要成员。
struct net_device {
int (* ndo_open) (struct net_device *dev);
int (*ndo_stop) (struct net_device *dev);
int (* ndo_start_xmit) (struct sk_buff *skb, struct net_device *dev);
...
}
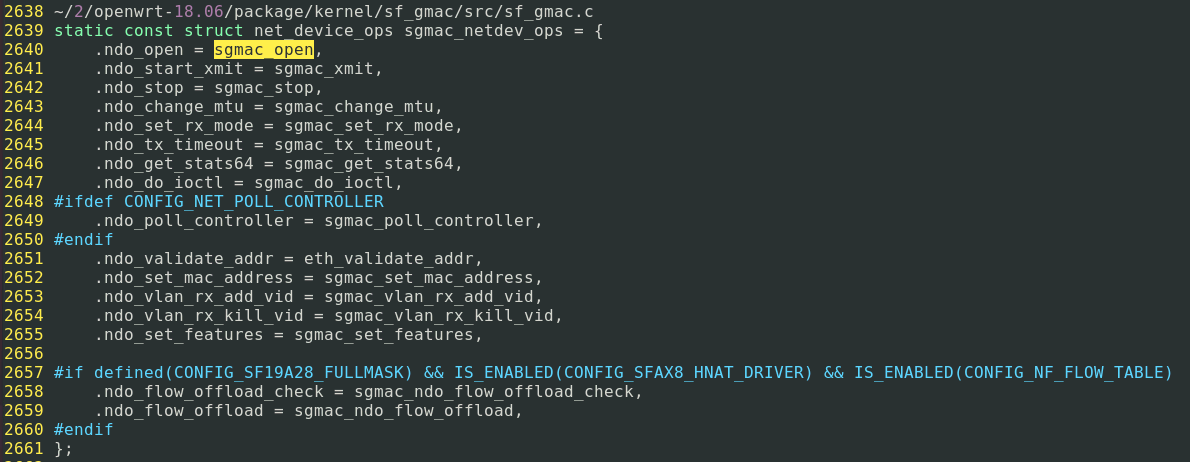
Siflower GMAC Device Driver将其功能注册到Linux,如下所示。
static const struct net_device_ops sgmac_netdev_ops = {
.ndo_open = sgmac_open,
.ndo_stop = sgmac_stop,
.ndo_start_xmit = sgmac_xmit,
...
}
4.3 GMAC的初始化顺序
本节给出GMAC驱动程序初始化的简要流程图。 这里提供的步骤作为GMAC初始化的流程。

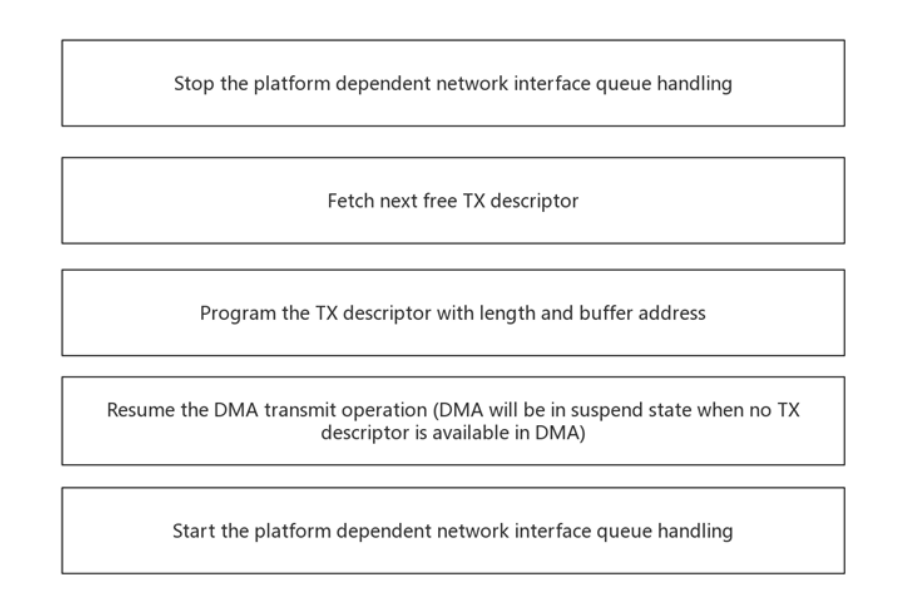
4.4 TX通路的编程指南
发送路径在OS准备好发送缓冲区时开始。 内核调用/调用在netdev-> ndo_start_xmit处注册的函数。 在驱动程序注册函数(sgmac_xmit)中执行的操作以流程图的形式提供。 传输在正常执行上下文中处理,这只不过是在进程上下文中,以及在中断上下文中部分地传送(将传送的缓冲存储器交给OS)。 详细描述请参考中断服务程序序列。
4.5 中断服务程序编程指南
在Linux中,接收是通过中断进行的,而不是在内核中注册处理收到的数据包的函数。 接收完全在内核注册的中断服务例程中处理。 设备生成传输完成中断(在传输数据包后生成,详情请参阅传输路径),表示数据包传输完成。
注:流程图仅解释在发送和接收过程中没有错误的情况下的操作顺序。 出现错误时,应妥善处理,以免发生系统故障。
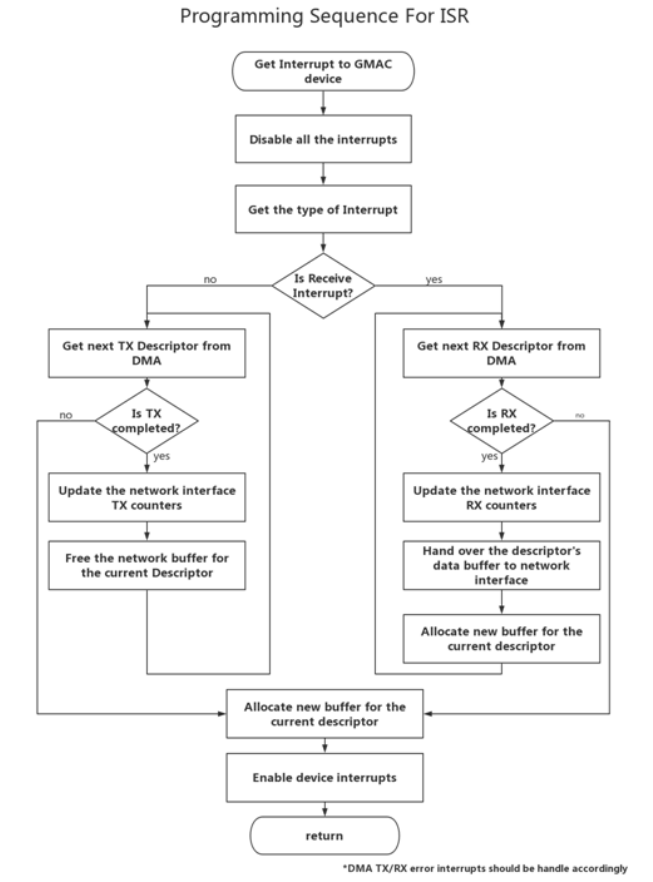
4.6 描述符
GMAC支持描述符的环和链结构,而在驱动程序中,我们选择描述符的环模式。 我们提供了Both发送器和Received描述符队列,每个队列都包含64个描述符。 要更改描述符的数量,请相应地更改sgmac.c文件以进行以下操作。
#define DMA_TX_RING_SZ 64
#define DMA_RX_RING_SZ 64
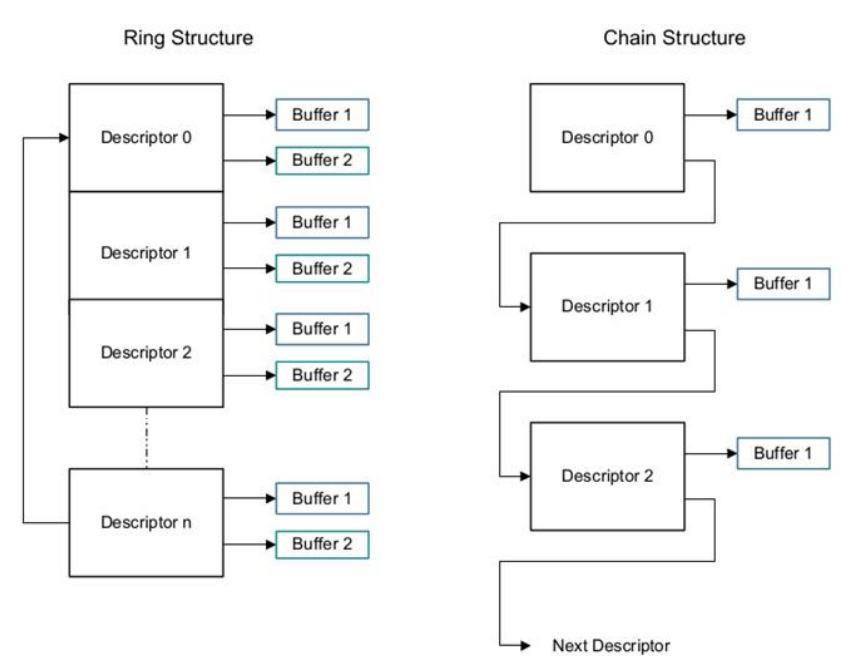
注意:所提供的中断服务程序无法处理指向环形操作模式下的数据缓冲区的buffer2,因此我们不会在设备驱动程序中使用它。
4.6.1 主机数据缓冲区对齐
TX和RX数据缓冲区对起始地址对齐没有任何限制,缓冲区的起始地址可以与四个字节中的任何一个对齐。 但是,DMA总是启动写传输,地址与总线宽度对齐,并且字节通道中的虚拟数据(旧数据)无效。 这通常发生在传输以太网帧的开始或结束时。 设备驱动程序应根据缓冲区的起始地址和帧的大小丢弃虚拟字节。
4.6.2 备用(增强)描述符结构
GMAC支持以下两种类型的描述符:普通描述符和增强描述符。 正常描述符可以有4个DWORDS(16字节),允许数据缓冲区最多2048字节。 增强描述符可以有8个DWORDS(32字节),已经实现支持高达8KB的缓冲区(对巨型帧有用)。 它们之间的主要区别在于TDES0,TDES1和RDES1中的控制和状态位的重新分配,并且核心还需要增强描述符来支持全IPC卸载和IEEE 1588时间戳,所以我们选择增强描述符 设备驱动程序。
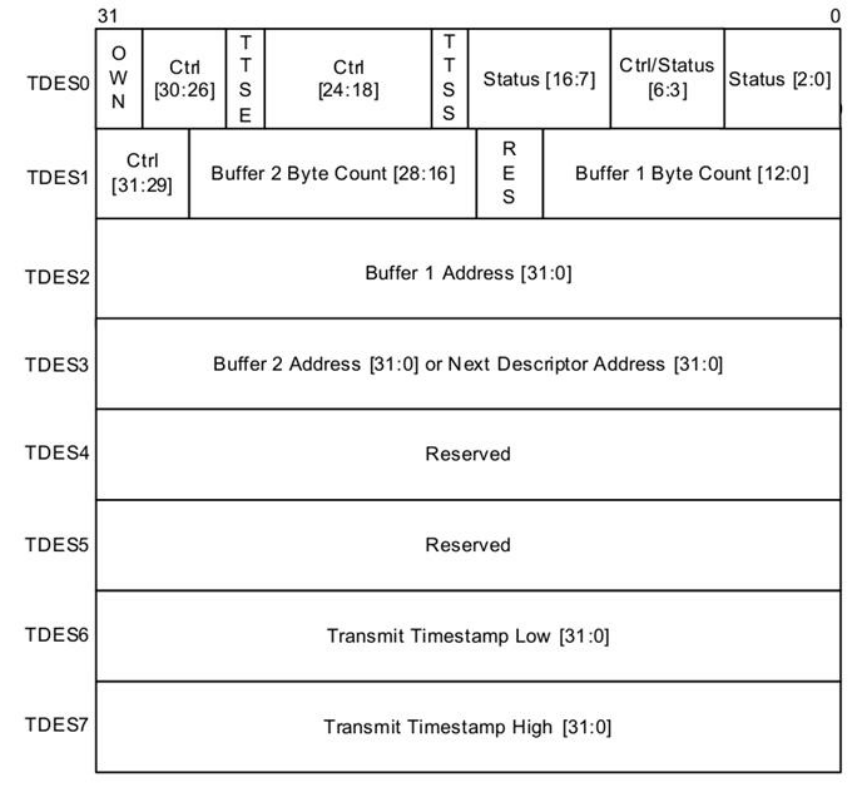
4.6.3 发送描述符
发送描述符结构如图3所示。设备驱动程序必须在描述符初始化期间对控制位TDES0 [31:18]进行编程。 当DMA更新描述符时,它将回写除OWN位(它清除)之外的所有控制位并更新状态位[7:0]。
通过提前支持时间戳,可以通过设置TDES0的位25(TTSE)为给定帧启用时间戳的快照。 当描述符关闭时(也就是说,当OWN位被清除时),时间戳被写入TDES6和TDES7。 这由TDES0的状态位17(TTSS)指示。
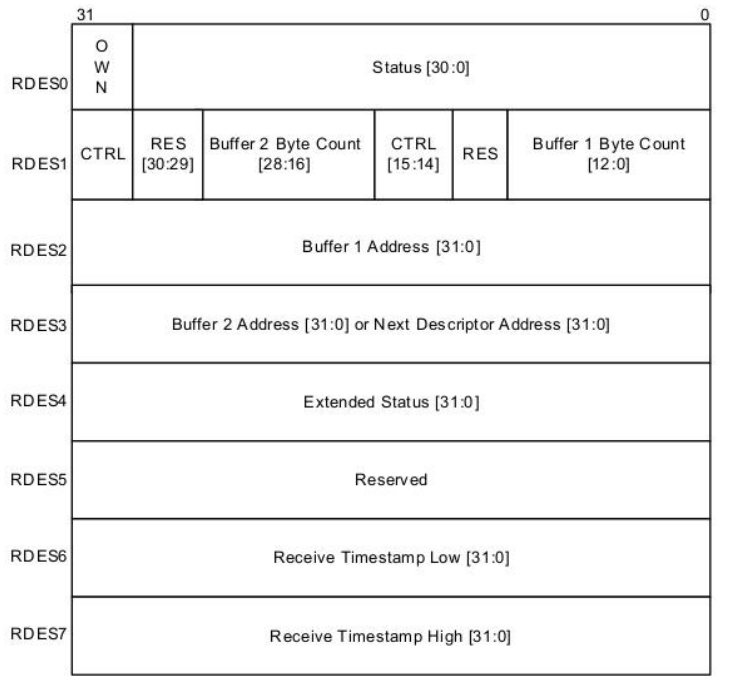
3.6.4 接收描述符
接收到的描述符的结构如图4所示。当我们使用Advanced Timestamp和IPC Full Offload功能时,它可以有32个字节的描述符数据(8个DWORD)
4.7 编译
本节仅适用于Siflower提供的设备驱动程序。提供驱动程序包以及一个makefile,它允许将驱动程序编译为模块。运行make clean清理中间文件。
make clean
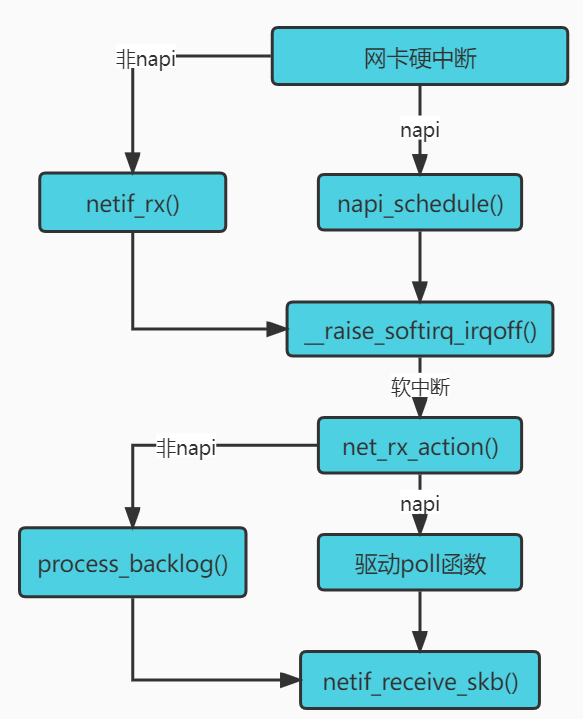
5 内核收包部分
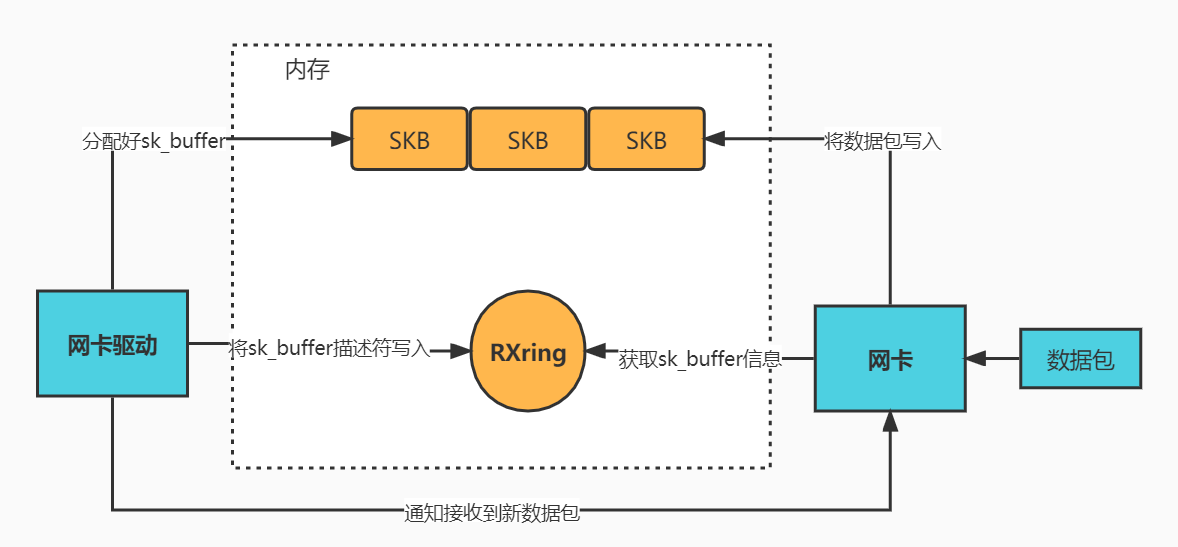
5.1 大致流程
- 加载网卡驱动,做初始化(包括poll函数)
- 网卡驱动需要在内存中申请一个缓冲区叫 sk_buffer
- 当收到数据包,就把数据包的 sk_buffer分配好,描述符存进ring buffer
- 网卡读取(通过DMA)ring buffer信息,获取sk_buffer地址和大小
- 网卡(通过 DMA)将包 copy 到内核内存中的 ring buffer
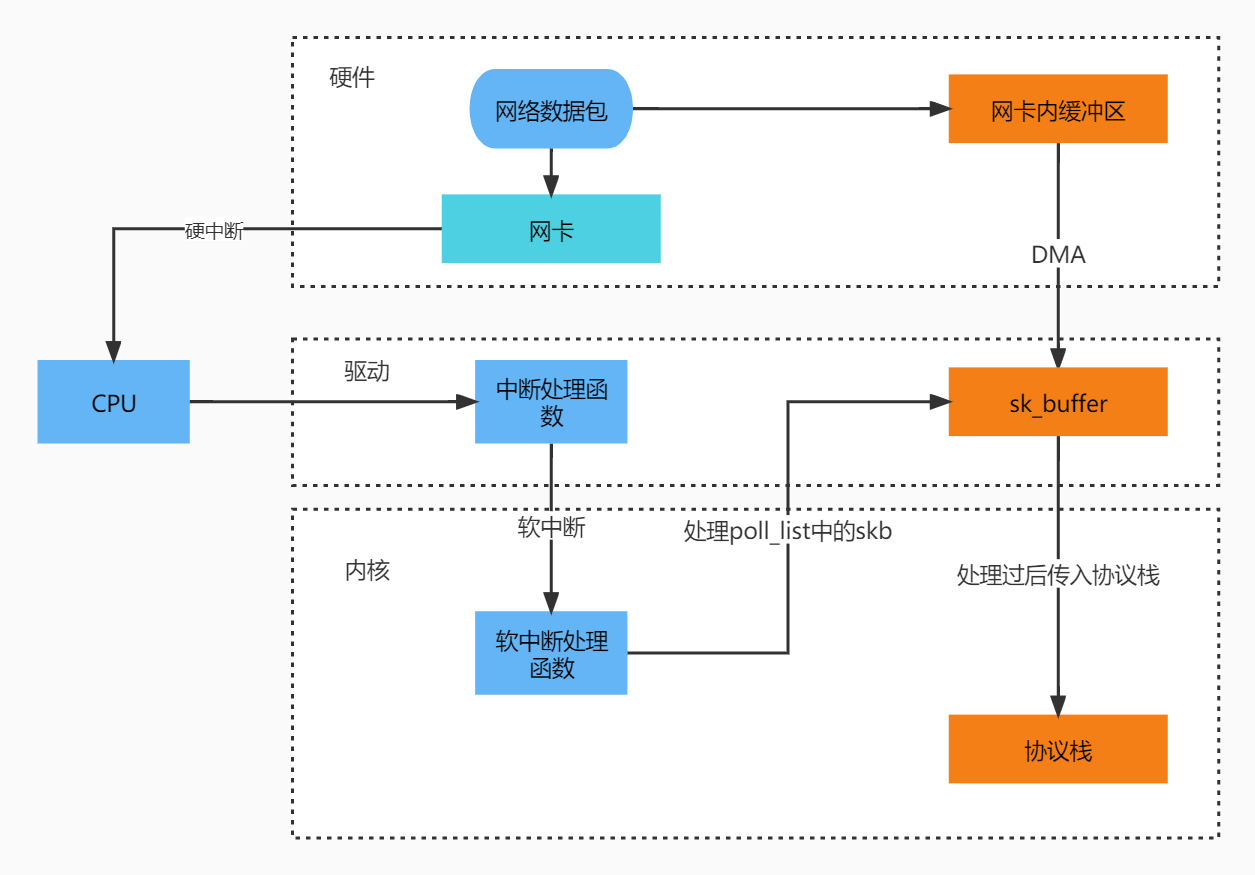
- 网卡会向CPU发起一个硬中断,告诉CPU有网络数据到达。
- CPU调用网卡驱动注册的硬中断响应程序
- 将网卡设备dev放入poll_list之中,然后调用软中断
- 驱动调用napi,开始轮询(poll),从ring buffer收包
- 这些数据包以skb的形式传入更上层的协议栈。
- 协议栈处理包,将他们传入socket接收队列
5.2 具体代码部分
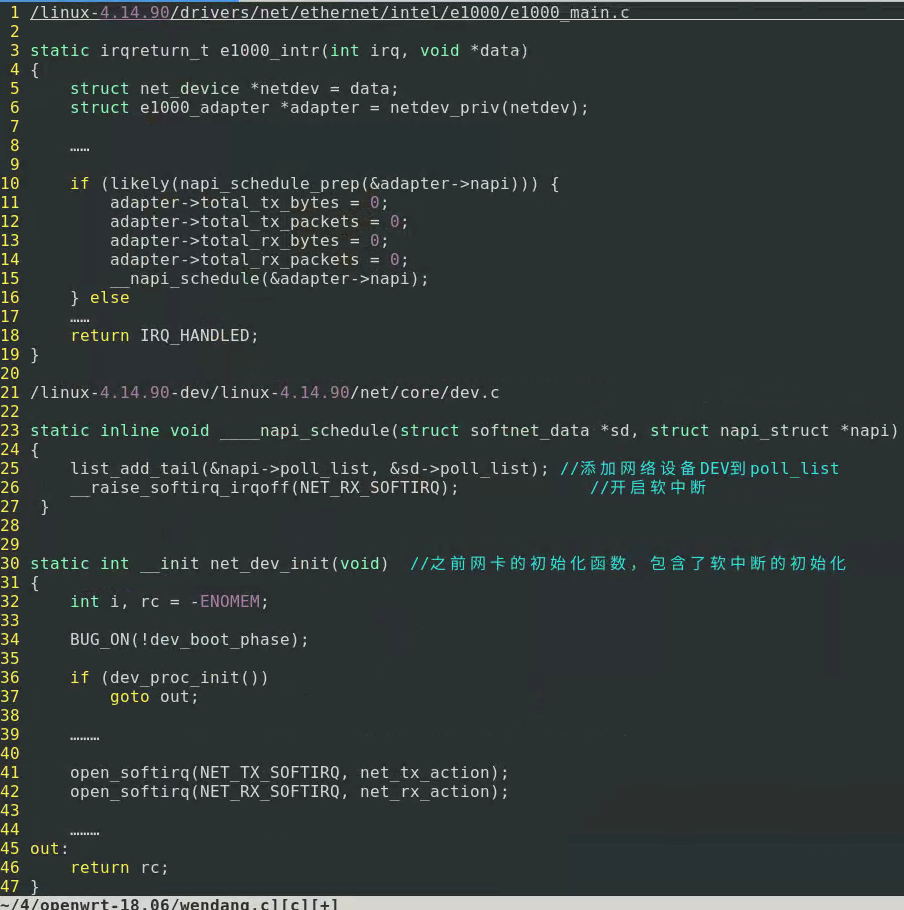
以e1000网卡驱动为例子,使用napi机制。/linux-4.14.90/drivers/net/ethernet/intel/e1000/e1000_main.c
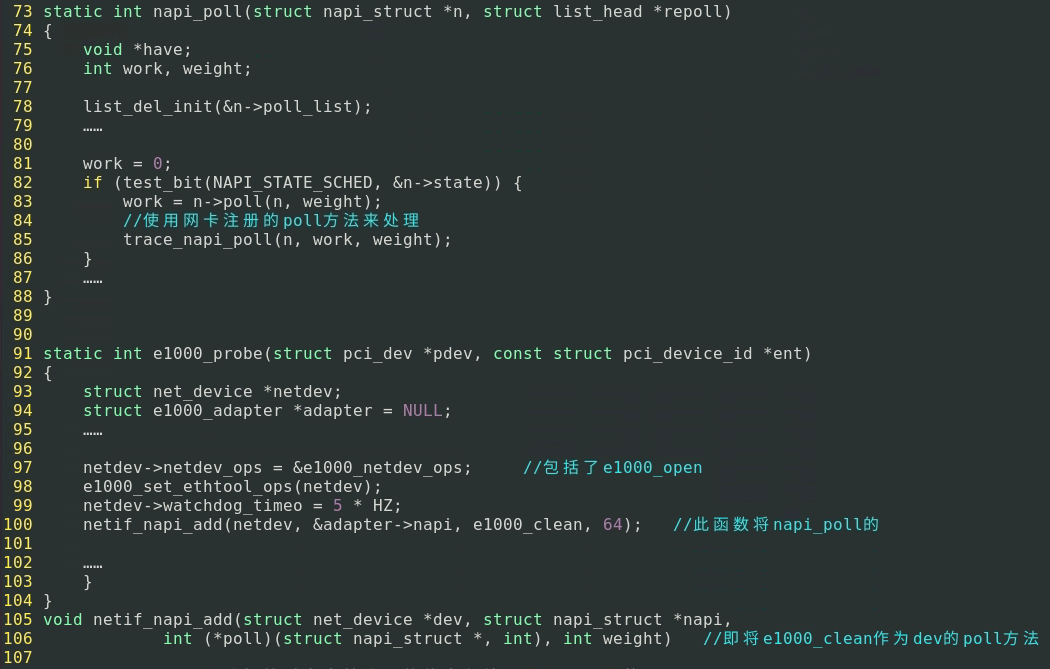
网卡驱动的初始化由e1000_probe开始。
硬中断中,e1000_probe→e1000_open,open函数对网络设备的数据结构做了初始化,特别是调用的setup_rx_resources为环形缓冲区做了初始化。
e1000_open→e1000_setup_rx_resources、e1000_request_irq。request_irq向系统申请中断号。
request_irq→e1000_intr。e1000_request_irq注册了硬中断处理函数为e1000_intr,其先添加网络设备dev到poll_list之后又调用了_napi_schedule。
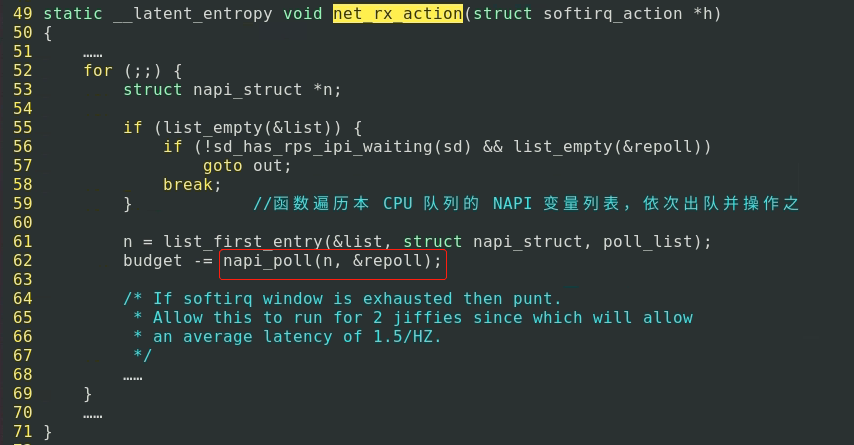
来到/linux-4.14.90-dev/linux-4.14.90/net/core/dev.c
_napi_schedule代码中 __raise_softirq_irqoff(NET_RX_SOFTIRQ);触发了一个值为 NET_RX_SOFTIRQ 的软中断,在软中断向量表中找到对应的中断程序执行, 也就是网卡初始化函数net_dev_init()函数中的代码:open_softirq(NET_RX_SOFTIRQ, net_rx_action);之中的net_rx_action()
net_rx_action()中的napi_poll里面,又使用了网卡注册的poll方法来处理数据,这里的poll方法是e1000_clean,里面主要是缓冲队列中接收全部数据,将
sk_buffer中的网络数据包送到内核协议栈中注册的ip_rcv函数中
小结:
__napi_schedule
->进入软中断
->net_rx_action
->napi_poll
->驱动注册的poll
->napi_gro_receive
-> napi_skb_finish
->napi_receive_skb_internal
->napi_receive_skb_finish
->napi_receive_skb_core
->deliver_skb
最后到pt_prev->func这一句结束,后面就是协议栈的部分。
上述流程在/openwrt-18.06/package/kernel/sf_gmac/src/sf_gmac.c中原理也一样,使用platform总线的形式来体现。具体函数sgmac_probe:
->sgmac_netdev_ops 设备操作函数的初始化
->netif_napi_add将sgmac_poll设置为napi_poll函数
->sgmac_interrupt为中断处理函数
->napi_schedule
->net_rx_action
->napi_poll
->sgmac_rx
->netif_receive_skb or napi_gro_receive
6 内核发包部分
6.1 大致流程
- 将用户要发的数据逐渐加上APP头部,TCP头部,IP头部,以太网头部,形成以太网帧。
- 用户数据从应用层、网络层、到数据链路层,传入sk_buffer
- 再如同rx步骤一般,将描述符传入一个tx ring buffer,又网卡读取,
- DMA到网卡缓存区,发送
- 发送完毕后给CPU发起硬中断
- CPU再触发软中断进行skb的清理和tx ring buffer
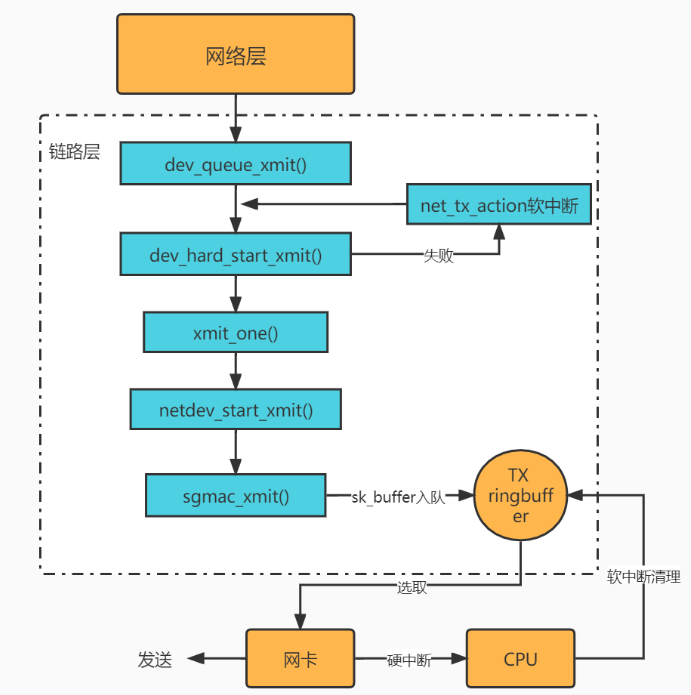
6.2 具体代码部分
dev_queue_xmit: netdevice子系统的入口函数,在该函数中,会先获取设备对应的qdisc,如果没有的话(如loopback或者IP tunnels),就直接调用dev_hard_start_xmit,否则数据包将经过Traffic Control模块进行处理,再进入dev_hard_start_xmit函数。
其中dev_queue_xmit已经完成了选择正确的发送队列,;保存当前的硬中断(IRQ)状态,并通过调用 local_irq_save 禁用 IRQ;获取当前 CPU 的 struct softnet_data 实例;将 qdisc 添加到 struct softnet_data 实例的 output 队列中;
在/openwrt-18.06/package/kernel/sf_gmac/src/sf_gmac.c
可以得知设备操作函数结构体sgmac_netdev_ops的start_xmit为sgmac_xmit,它会启动数据包的发送。当系统调用驱动程序的xmit函数时,需要向其传入一个sk_buffer结构体指针,使得驱动程序能获取从上层传递下来的数据包。
sgmac_xmit():
->dev_kfree_skb_any() linux-4.14.90-dev/linux-4.14.90/net/core/dev.c
函数 dev_kfree_skb_irq 可以将 skb 添加到队列中以便稍后释放。 设备驱动程序通常使用它来推迟释放消耗的 skb。
->__dev_kfree_skb_irq()
->raise_softirq_irqoff(NET_TX_SOFTIRQ)调用了一个值为NET_TX_SOFTIRQ的一个中断函数
->net_tx_action
->completion_queue while 循环将遍历这个列表并__kfree_skb 释放每个 skb 占 用的内存
->output queue
->tx_map
->...netdev_tx_sent_queue 到此发送完成
7 FAQ
文档信息
- 本文作者:Phoenix
- 本文链接:https://siflower.github.io/2022/03/11/ethernet_trx_guide/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)